Following the recommendation from the fourth talk, I also watched "Big Data, Data Science and Statistics. Can we all live together?" by Terry Speed. He compared the description of data science with his research profile and said:"I guess I have been doing data science after all." Precisely what I felt.
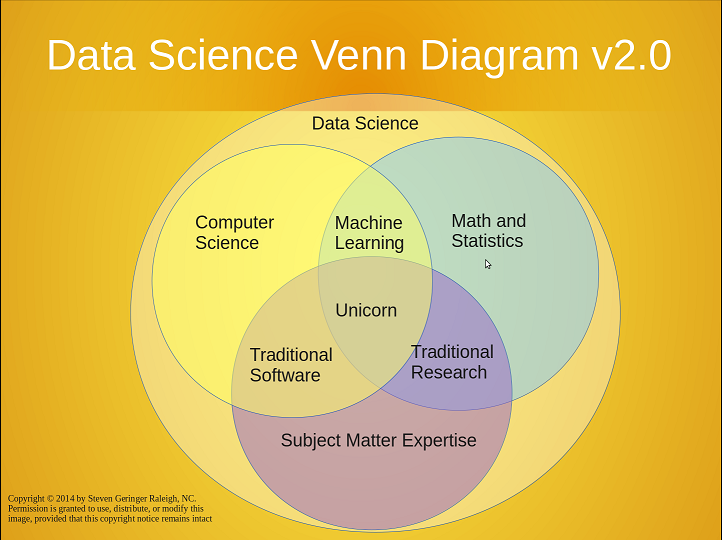
These two videos touched on several important areas statisticians need to work on in order to be more involved in Data Science (if you want to be more involved, of course). In particular, we need to equip our students with problem solving skills, programming and "hacking" skills, collaboration and communication skills. These skills cannot be taught in the conventional pedagogy in Statistics. It would require more real-data projects with open-end problems and opportunity to collaborate with non-statisticians. It would require to encourage the students to be never satisfied with their models, their codes and their visualization/presentation, and strive for better models, faster algorithms and clearer presentation. This has been a focus in every research project of mine with my PhD students. I love how Professor Lance Waller from Emory University hacked his business card to give himself a title of "unicorn trainer." My current PhD students are packing up domain knowledge and computing skills in parallel computing, data management and visualization in their individual projects, in additional to their research in statistics and machine learning. In other words, they are indeed becoming unicorns.
Next semester, I will be teaching a course on "Applied Data Science" that is data-centric and project-based. It will not be organized by methodology topics as the pre-requisites cover both statistical modeling and machine learning. Every 2-3 weeks, we will explore analytics on a type of non-traditional data. There will be a lot of discussion, brain-storming, real-time hacking, code reviews, etc. It is intended for graduate students in Statistics to gain more data science skills and overcome the fear towards the real-world messiness in real data (big or small). Hopefully, we can get some unicorns-to-be out of this course as well.
Incidentally, I ran into ASA's statement of the role of Statistics in Data Science today. My favorite quote from this statement is:
For statisticians to help meet the considerable challenges faced by data scientists requires a sustained and substantial collaborative effort with researchers with expertise in data organization and in the flow and distribution of computation. Statisticians must engage them, learn from them, teach them, and work with them.
No comments:
Post a Comment